


昨天提到微软和AWS在其云平台上部署了 DeepSeek-R1 模型,而因为 DeepSeek 爆火导致股价一度下跌 17% 的英伟达最近也在其硬件和生态上部署了 DeepSeek-R1。
这也体现了英伟达的格局,前期接入 DeepSeek-R1 的产品是英伟达最新的 GeForce RTX 50 系列 GPU 以及 NIM 微服务。
让我们了解下微软的生态体系。
1:什么是推理模型
DeepSeek-R1 模型是一个推理模型,在解决复杂问题的时候,会花大部分时间进行思考和反思,整个过程和人类的思考方式类似,这种模式也叫做 test-time scaling,会在推理过程中动态分配计算资源。
推理模型的优势就是能够深入理解用户的需求,为 agentic ai 工作流提供更好的基座模型。
2:DeepSeek-R1 为什么与众不同
DeepSeek-R1 是一个拥有 6710 亿参数的混合专家(MoE)模型,可以将子任务分配给更小的专家进行推理,从而减少计算资源。
DeepSeek-R1 通过蒸馏技术产生了 6 个较小的学生模型,比如 DeepSeek-R1-Distill Llama-8B,将 DeepSeek-R1 模型的能力传递给较小的 Llama 模型。
至于现在为什么推荐使用小型推理模型,下面会讲到。
3:GeForce RTX 50 系列 GPU
英伟达最新一代的 PC GeForce RTX 50 GPU 系列,配置了专用的第五代 Tensor Cores,采用和 Blackwell GPU 一样的架构。
为啥提到 RTX 50 系列 GPU 呢?因为英伟达一直有一颗 PC 的芯,希望将 GPU 的能力用在 PC 上,而不仅仅是云端服务器上。
而 DeepSeek-R1 极致的推理性能,加上 GeForce RTX 50 GPU 强劲能力,可以是天作之合。
下图是 DeepSeek-R1 系列模型运行在各种 GPU 上的性能比较,以 Tokens/s 指标作为参考标准。
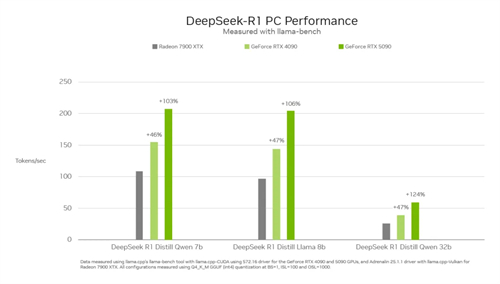
以 DeepSeek-R1-Distill Llama-8B 来说,RTX 5090 比上一代的 RTX 4090 和 AMD 7900 XTX,Tokens/s 吞吐量分别提高了 47%、106%。
4:NVIDIA NIM microservice
英伟达的 NIM 微服务可以将主流的模型进行容器化,运行在各种基础设施上,未来 DeepSeek-R1 模型 NIM 微服务将可以从 NVIDIA AI Enterprise 软件平台上下载使用。
经过英伟达测试,在单个 HGX H200 系统上,通过部署 DeepSeek-R1 模型 NIM 微服务,每秒可以处理 3872 tokens。
为什么吞吐量争拗?在单个 HGX H200 系统上,使用NVLink和NVLink Switch连接8个H200 GPU,能充分利用高达 900 GB/s的NVLink带宽。
如果想对 DeepSeek-R1 进行一些微调,还可以使用 NVIDIA AI Foundry 中的 NVIDIA NeMo 定制自定义的 DeepSeek-R1 NIM 微服务,NVIDIA NeMo 主要用于构建、定制、部署多模态的生成式AI模型或 AI 代理系统。
最后一句话,英伟达不仅仅有 GPU,整个软件生态是很完善的。



